智能体协作(Agent Collboration)探索与实践
在未来能够创造和调用多少个智能体,就会像现在要求熟练使用office办公软件一样必要,如何设计和构建工作流workflow、如何与AI交流、如何高效使用各种AI工具将成为必备技能
1 一条视频的启发
未来预测:在未来能够创造和调用多少个智能体,就会像现在要求熟练使用office办公软件一样必要
核心技能:如何设计和构建工作流workflow、如何与AI交流、如何高效使用各种AI工具
平台推荐:
code/dify 智能体平台;元器智能体/文心智能体平台
学习路径:
- 感知智能体工作流程:在智能体平台找别人做好的agent玩一玩
- 详细了解工作流编排:拆解别人做好的agent,了解流程
- 模仿做一个智能体
- 补充底层逻辑:b站 吴恩达关于智能体的分享(智能体设计的核心模式:反思/工具使用/规划/多智能体协作)。进一步深入理解为何这样使用(不是底层原理,不是敲代码)
- 拆解一天的工作流程:将重复/需要跨软件操作的环节全部交给智能体
- 输出成果,持续学习和创造,封装和积累数字资产:演示智能体的具体使用场景
未来方向:
- 智能体搭建(业务专家/运营/为降本增效):继续基于智能体平台,重点研究各种第三方开发的更复杂的插件,和如何有效搭建AI知识库(如何将本地word/PDF投喂给AI变为专用的agent,称为某个专业领域的万事通)
- 开发者(业务专家和技术专家之间/当前最稀缺):code代码节点、开发功能/功能更强大的工作流/自己开发的插件,提供给code平台其他使用者来调用,使用开源框架(为更高定制化需求)
- LangChain/CrewAI
- 不是从python开始学起,而是把github上的开源项目在本地跑起来
- 智能体在专业场景是如何运行的、知道链和工具在代码层面怎么被调用
2 初试Dify
2.1 创建体验
2.1.1 搭建AI图片生成应用——参宿四画廊
使用 dify + gpt 4o + Stability 搭建一个AI图片生成应用
Stability:一个专注于生成媒体(图像、音视频)的人工智能工具/模型
获取和添加API密钥
获取
Stability API密钥 (Stability AI - Developer Platform),在Dify - 工具中添加Stability插件,并将API密钥添加其中配置模型供应商
使用LLM撰写生成图片的提示词prompt,可以在
头像 - 设置 - 模型供应商中更改LLM提供商
- Free 版本的 Dify 提供了免费 200 条 OpenAI 的消息额度
- groq 平台提供了 Llama 等 LLM 的免费调用额度(API Keys - GroqCloud)
构建Agent
在
Dify - 工作室 - 创建空白应用,选择Agent选择
LLM:gpt 4o选择
工具:Stability撰写提示词
输入提示词(可以使用Markdown风格)
不撰写提示词
使用提示词生成器
疑惑解答:
Q:Stability已经是一个图片生成模型了,为什么还需要调用gpt 4o?
A:Stability难以理解人类抽象的语言描述,需要gpt 4o进行辅助翻译为更加具体、富含关键信息的专业提示词。gpt 4o(LLM,大脑,翻译官),将你输入的想法转换为机器可以高效执行的指令;stability(专业模型,手,执行官),接收gpt 4o输出的的精确指令高效执行绘图。
Q:在Dify应用的提示词中写的内容,是写给应用中调用的LLM的?还是写给使用的专业模型的?
A:是写给LLM的,工具流程决定了提示词中的内容由Dify编排传递给LLM,以此定义LLM的角色和任务。LLM再生成精确的指令给Stability去执行。Dify串联这一切流程。
2.1.2 搭建个人在线旅游助手——银河系漫游指南
使用 dify + SerpAPI + webscraper + Wikipedia 搭建一个个人在线旅游助手
SerpAPI:从联网的搜索引擎中提取数据的谷歌工具(提供了免费的100次消息额度)
webscraper:dify内置的爬虫工具,从指定的网页中抓取内容
Wikipedia:dify内置的知识来源工具,进行维基百科搜索和片段/网页提取
搭建步骤:3
获取和添加API密钥
获取
SerpAPI密钥 (Stability AI - Developer Platform),在Dify - 工具中添加API密钥添加其中构建Agent
在
Dify - 工作室 - 创建空白应用,选择Agent选择
LLM:gpt 4o选择
工具:Google、websraper、wikipedia撰写提示词
设置变量,限定用户输入
疑惑解答:
Q:用wikipedia+google+websraper+gpt 4o在dify上造了一个旅游助手,但是我个人觉得它生成的计划还不如我用一个deepseek生成的结果全面
A:构建一个可靠且高效的Agent,远比简单地调用一个强大模型要复杂得多。在这个旅游助手(工具调用型Agent)中,工作流程是“1. 理解用户问题 -> 2. 决定调用哪个工具 -> 3. 执行工具获取信息 -> 4. 整合信息生成回答”,哪一个环节出现问题都会影响生成结果。所以可以通过“使用高质量/专业型API -> 优化清晰提示词 -> 设置后处理(生成后自我检查) -> 使用RAG(检索强化生成,建立高质量专属信息库)”进行相应改善。
2.1.3 搭建文章理解助手——无限进步
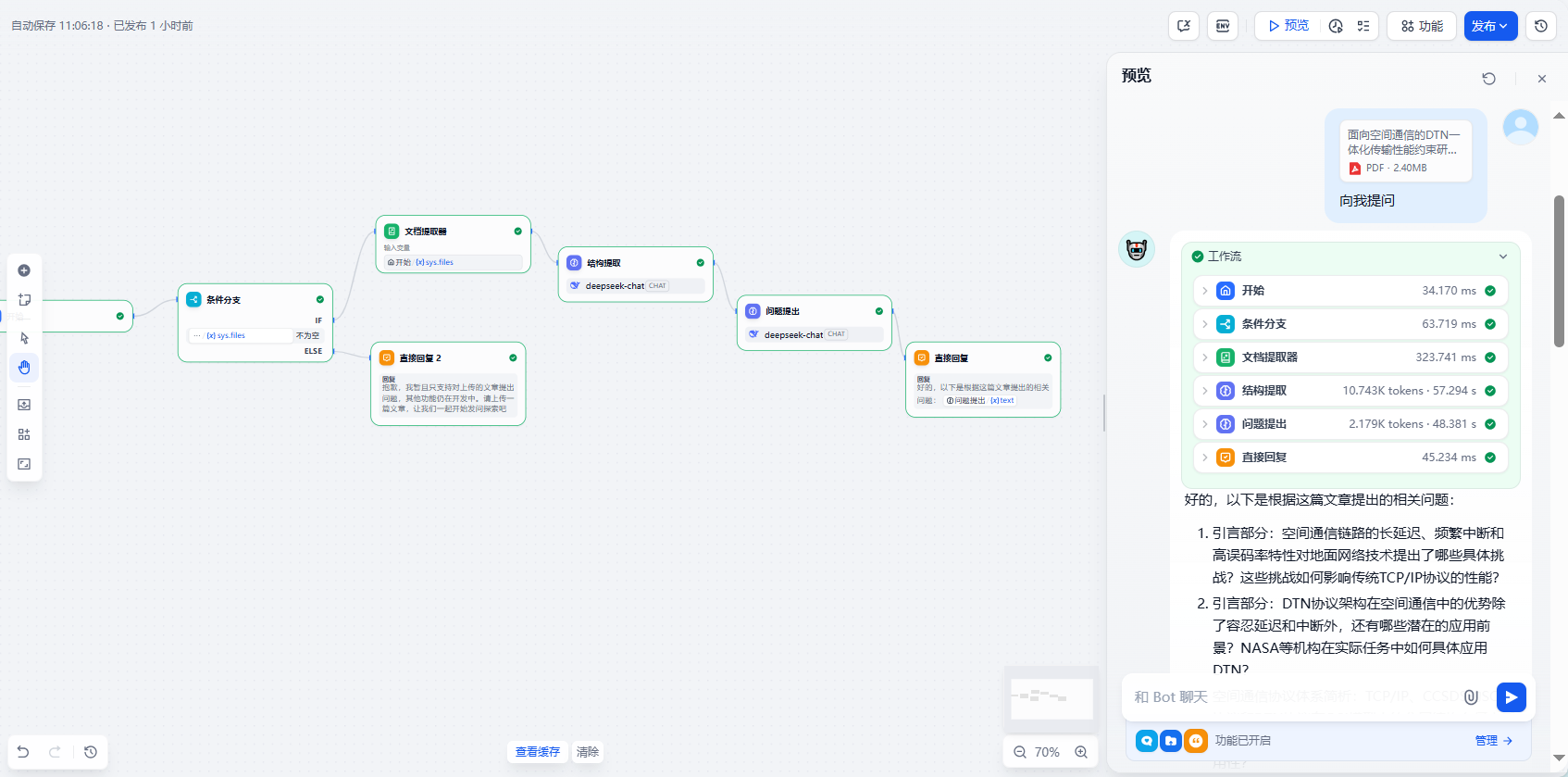
使用 文件上传 搭建一个文章理解助手,文章理解助手会根据上传的文档进行提问,协助用户带着问题去阅读论文等材料
搭建步骤:4
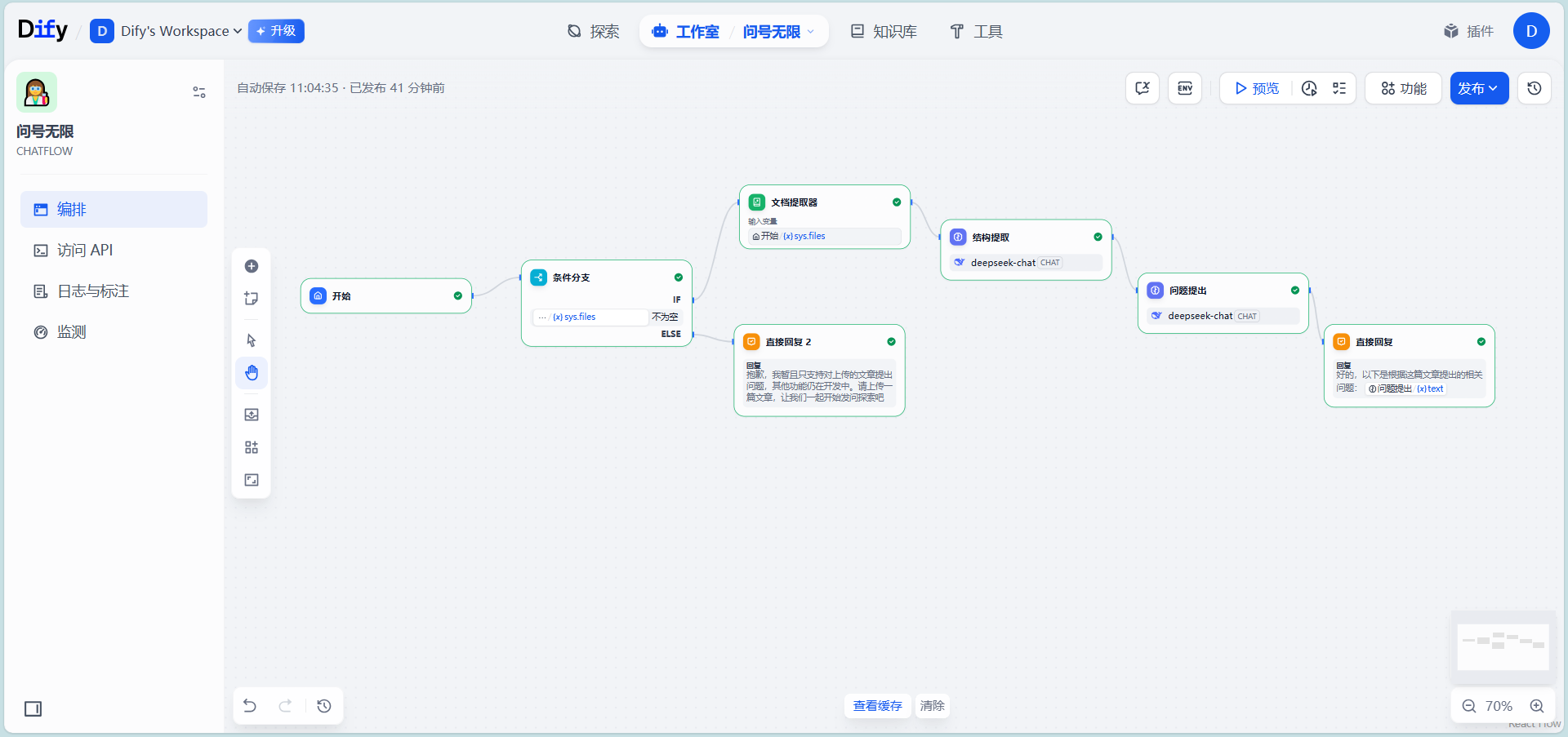
- 前期准备:工作室中创建
Dify-Chatflow,本节更换LLM为deepseek chat,需安装deepseek插件并添加API- 添加节点:
- 开始节点:添加输入字段类型为单个文件变量
file类型(处理多个文件时,选择文件列表array[file]类型)- 文档提取器节点:将文件变量
file类型作为该节点的输入,输出变量设置为text string类型- 创建两个LLM 节点:
- 结构提取:从原文内容中提取文章结构,总结关键内容,提示词中添加
文档提取器输出变量 {x}text- 问题抛出:从结构提取节点总结的内容中总结文章的问题,协助用户思考,提示词中添加
结构提取的输出变量 {x}text- 直接回复节点:回复中添加
问题抛出的输出变量 {x}text
疑惑解答:
Q:第一次使用付费的LLM的api,deepseek给出的价格是:缓存命中
0.5¥/输入百万tokens、缓存未命中4¥/输入百万tokens、输出12¥/输出百万tokens,之间有什么区别使之价格相差近十倍?A:成本不同,定价不同
- 缓存未命中
cache miss指用户输入了一个全新提示,LLM需要重头开始处理整个输入序列,会消耗大量GPU算力,覆盖的是电费+GPU折旧+数据中心运营+研发等所有高昂成本。- 缓存命中
cache hit指用户输入的提示是之前处理过的,LLM只需要从缓存中去除结果即可,主要是内存读写操作,消耗算力极小,覆盖的仅仅是内存占用和一点点数据传输的成本。
2.2 知识总结
2.2.1 Agent基本概念
Agent的定义
一种模拟人类行为和能力的AI系统(智能体),它通过自然语言处理与环境交互,能够理解输入信息并产生相应的输出
Agent的特点
具有感知能力,能够分析和处理各种类型的数据
调用和使用各种外部工具和API,扩展功能范围
灵活应对复杂情况,在一定程度上模拟人类的思考和行为模式(智能体)
2.2.2 提示词prompt工程的基础知识
prompt定义
用户提供给人工智能的指令或问题,用以引导或激发AI生成特定输出,是Agent的灵魂
提示词撰写技巧
使用markdown将提示词结构化
2.2.3 大模型的幻觉
即使输出的内容是错的,但为了努力回答用户而编造虚假内容的现象称为模型幻觉(Hallucinations)