阿里云HPN架构阅读报告
阿里云的HPN(High Performance Network)是针对解决AI训练集群网络中流量冲突、单点故障问题提出的网络架构,其采用非堆叠双ToR、双平面、多轨通信等技术优化了网络性能
Alibaba HPN: A Data Center Network for Large Language Model Training.
1. 前置知识
AI大模型训练集群网络的基础构成
前后端网络
- 前端网络 :主要负责管理流、数据加载、存储交互(如保存 Checkpoint)以及用户推理请求。它通常采用传统的以太网架构(TCP/IP)
- 后端网络 :专门用于 GPU 之间的参数同步和梯度交换(如 All-Reduce 算子),要求极高的带宽和极低的延迟,通常采用 RDMA(Renote Direct Memeory Access,远程直接内存访问)技术
服务器内外部通信
- 节点内 :一台服务器内的 8 个 GPU 之间通过 NVLink 互联,带宽极高(如 H100 的 NVLink 4.0 可达 900GB/s)
- 节点间 :当模型规模超出单机负载时,必须通过后端网络的网卡跨服务器通信。此时,后端网络的带宽远低于机内 NVLink,成为整体训练性能的瓶颈
集群之间通信
RDMA:允许 GPU 直接访问远程服务器的内存,无需 CPU 干预,从而显著降低延迟和 CPU 损耗
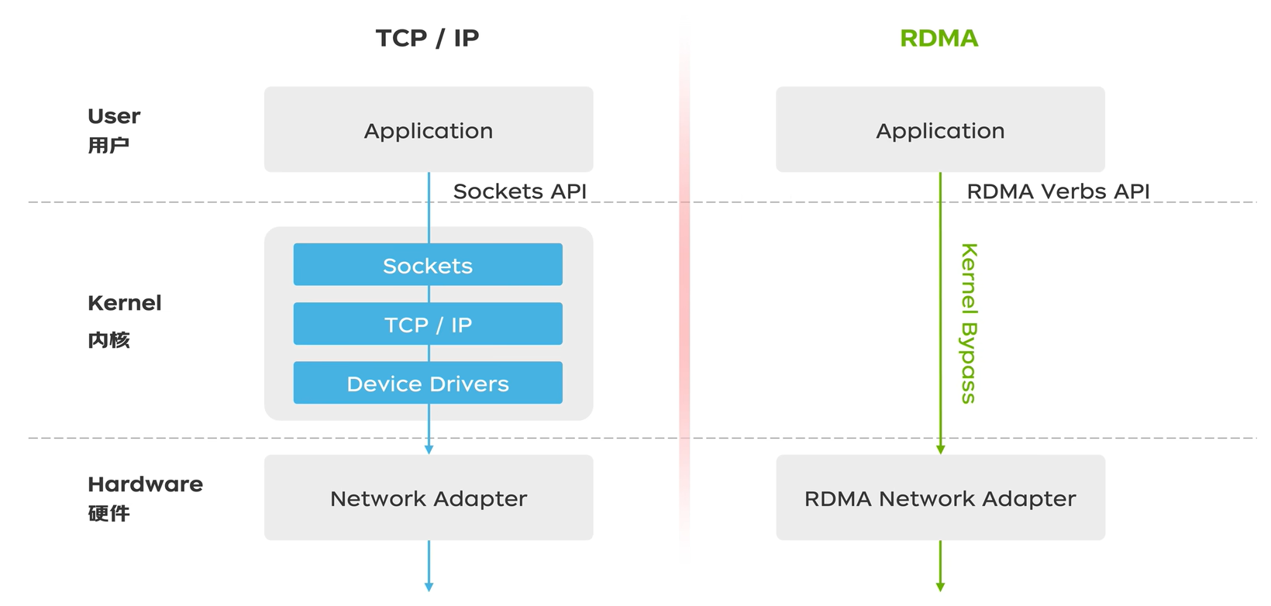
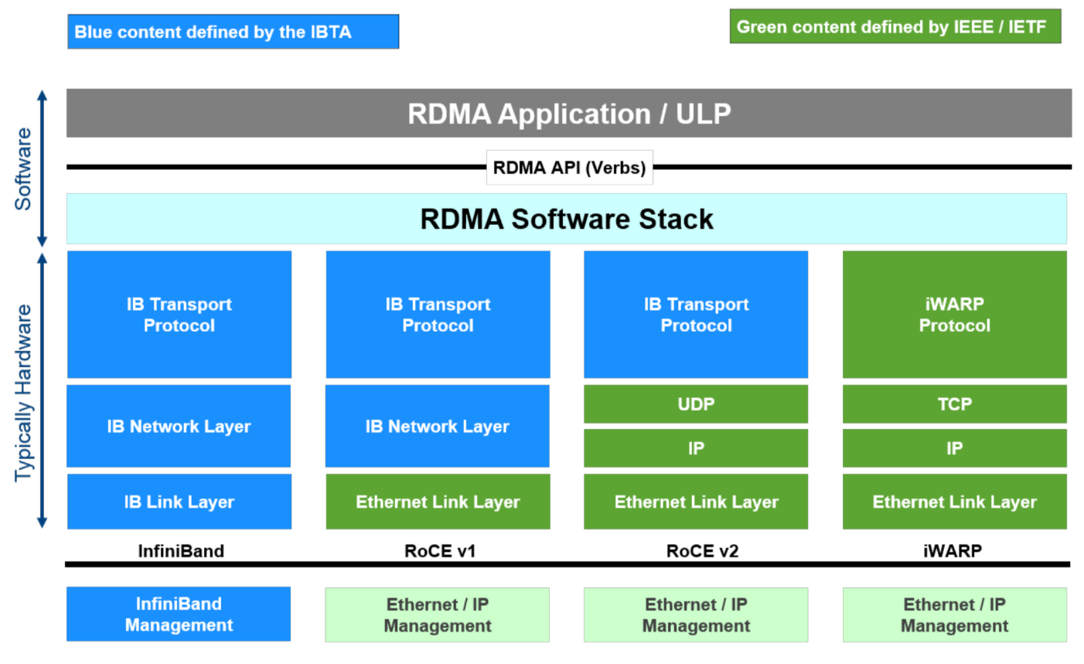
RoCE v2 (RDMA over Converged Ethernet,基于融合以太网的RDMA):一种在以太网上承载 RDMA 流量的协议。HPN 正是基于以太网和 RoCE v2 构建的高性能网络,旨在挑战传统的 InfiniBand (IB) 专用网络
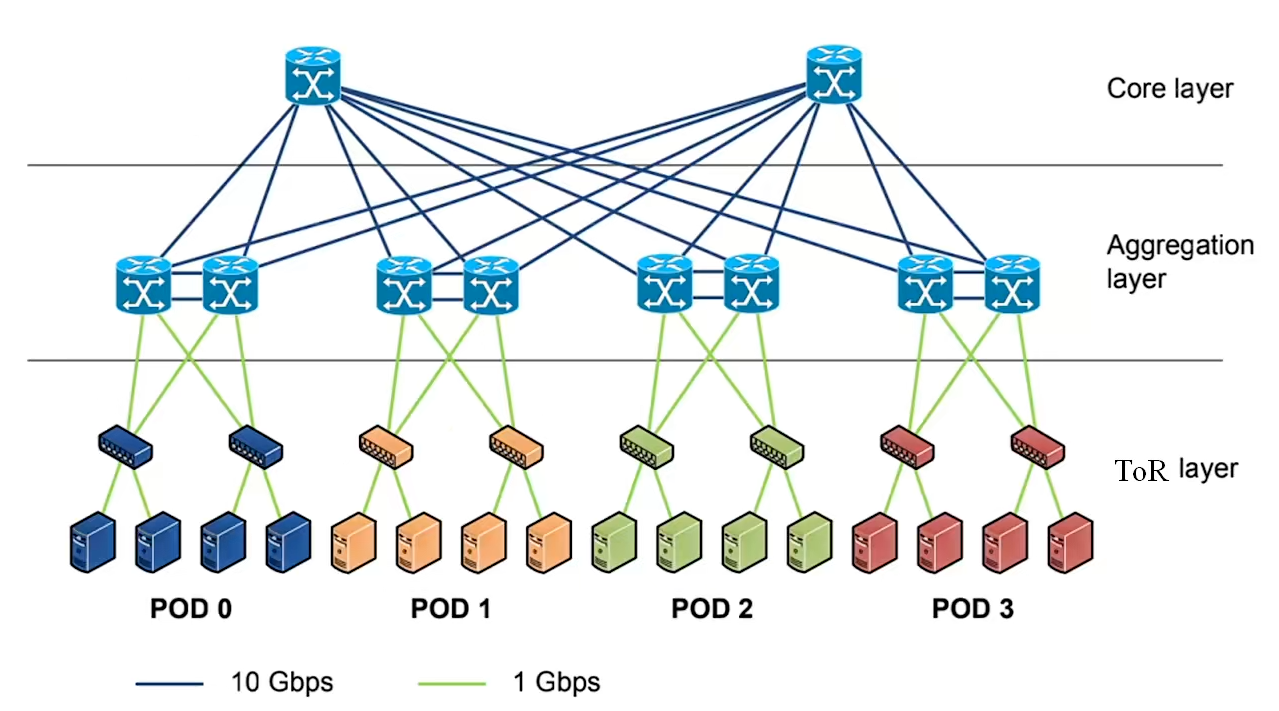
网络架构:Spine-Leaf 结构
接入层ToR——汇聚层Pod——核心层Core:链路冗余,多层跨轨
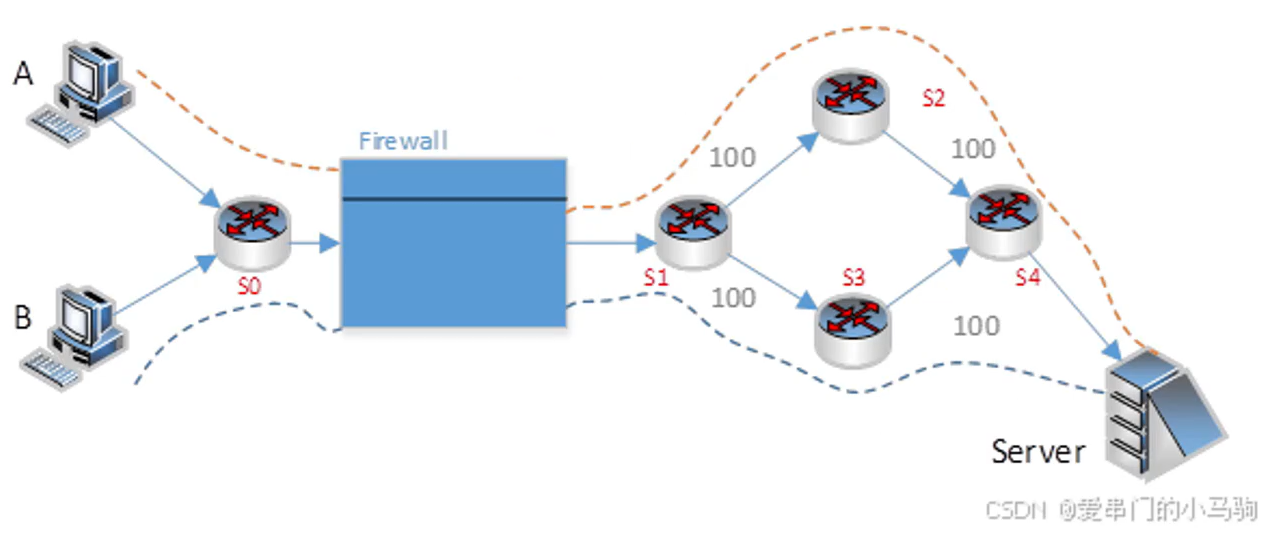
ECMP(Equal-Cost Multi-Path)等价多路由
ECMP定义:当网络中传输存在多条距离相等(开销一致)的路径时,ECMP允许路由器或交换机同时利用这些路径传输数据,而不是直走其中一条
工作原理:路由器根据IP报文的五元组信息(源IP地址、源端口、目的IP地址、目的端口地址、传输协议)组成的集合来计算一个哈希值,用得出的数值对可用路径取模,从而决定传输路径(哈希决策)
核心目的:保证同一条流(五元组相同的包)始终走同一条物理路径,防止乱序,降低传输协议的性能
2. 研究背景
2.1 核心问题
大模型训练的流量模式与一般云计算有所不同,ECMP面临大象流会导致哈希碰撞、哈希极化
AI训练流量特性导致负载均衡困难
网络利用率周期性突发:传统云计算流量模式相对稳定,每小时缓慢变化(Figure 1);LLM训练的网络流量存在周期性突发,需要足够高带宽避免丢包(Figure 2)
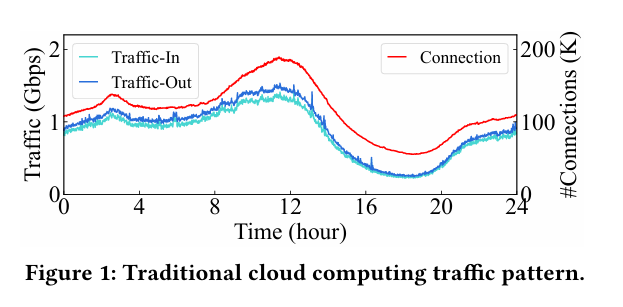
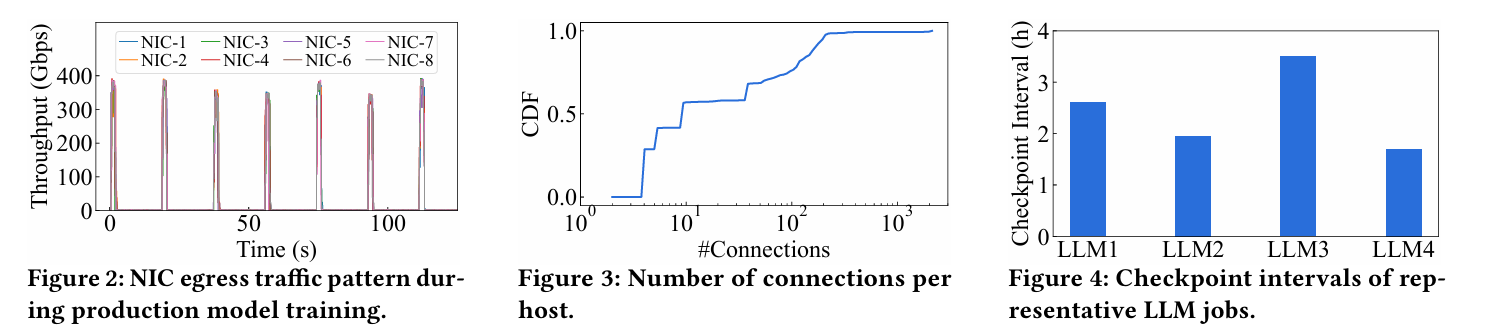
流量数量少:一般云计算实例通常产生数十万个连接;LLM训练中每个节点产生的连接少至及时到几百个(Figure 3),每个流需要发送的实际数据量巨大
负载不均:
- ECMP前提假设失效:传统数据网络中心假设网络中有大量流数目,采用ECMP负载均衡,用哈希算法将流量均匀地分布在网络中所有等效路径上;LLM训练仅涉及少量大流(大象流),采用ECMP会导致哈希碰撞,引起很多性能问题
- 哈希极化:传统数据中心采用3层网络架构,大流转发经过3次哈希计算,级联的哈希会产生更严重的负载不平衡,让网络深层的拥塞变得极其难以预测
AI大模型训练对网络故障更敏感
LLM训练对故障更敏感:LLM训练需要多个GPU合作完成多次迭代(持续几十天),一个GPU或主机故障了,可能会导致整个训练崩溃(Figure 4),造成较大经济损失
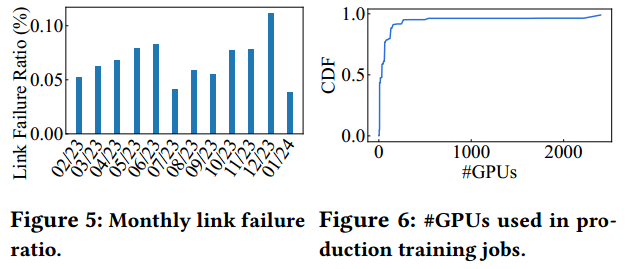
单点故障风险高:故障带来的经济损失高,传统网络架构中第二、三层有冗余链路,但第一层网卡与规定交换机之间(ToR)缺乏链路冗余,存在单点故障风险;LLM训练涉及设备规模大,几乎不可能保证没有网络设备发生故障(Figure 5、Figure 6)
2.2 相关研究
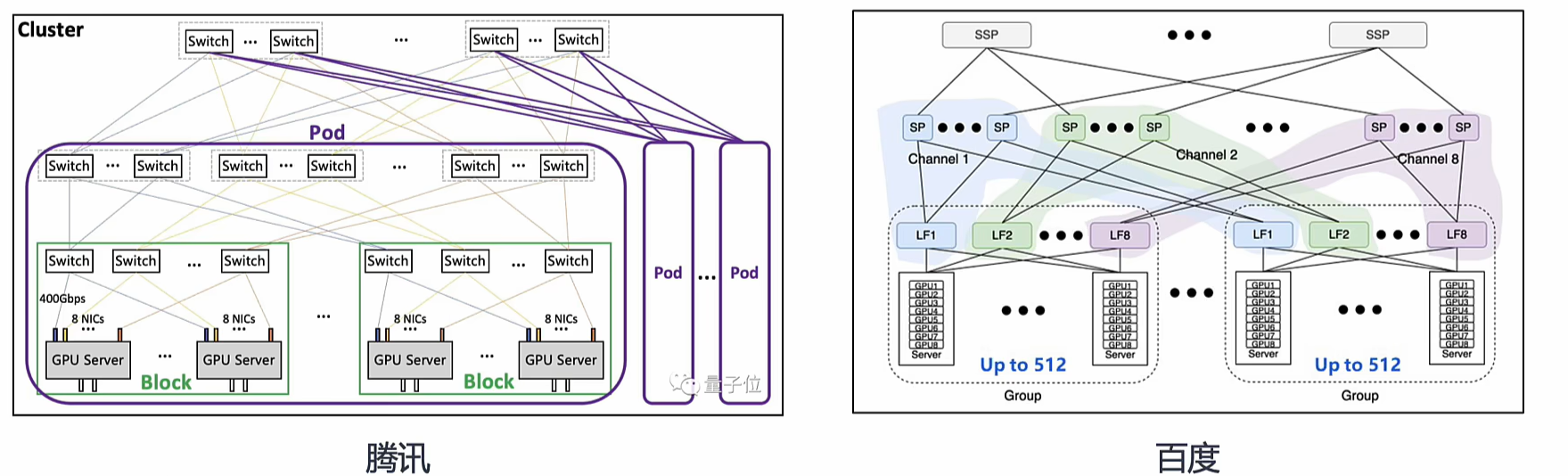
- 业界主流组网方案:国内头部企业万卡 AI 集群多采用三层盒式交换机搭建 1:1 无收敛 Clos 架构,服务器普遍按 8 卡 8 轨道接入设计,核心差异体现在交换机转发容量与单卡接入带宽维度。
- 传统高性能网络方案:InfiniBand(IB)专用网络凭借低延迟、高带宽成为 LLM 训练网络备选,但存在部署成本高、与以太网生态兼容差的问题;基于 RoCE v2 的以太网方案成本更低、扩展性更好,但受 ECMP 哈希碰撞、单点故障等问题制约,难以适配 LLM 训练的大流特性。
2.3 设计目标
- 可扩展性:支持千卡、万卡、十万卡
- 高性能,低延迟:尽可能减少网络跳数,从而减少延迟,提升ECMP路径选择的精准性
- 单ToR容错:避免单点故障
3. 解决方法
3.1 非堆叠双ToR上联消除单点故障
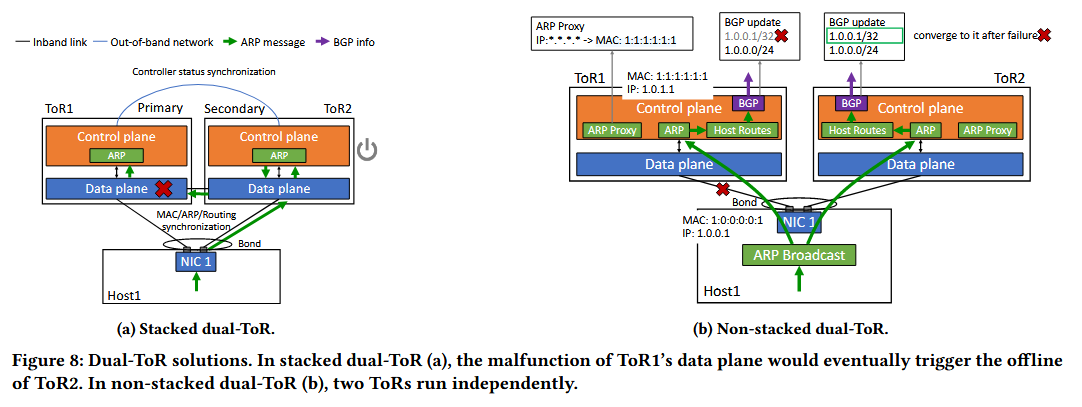
- 传统数据中心网络中的堆叠式双ToR:每个网卡两个端口通过一根连接到ToR交换机的电缆/光纤进行汇聚,易受交换机/链路故障影响,影响LLM训练
- 非堆叠双ToR:每个网卡的两个端口以主-备方式(端口配置相同IP与MAC地址,共享相同队列对上下文,流量切换不会导致活动流的中断)连接到不同的ToR,一个宕机另一个继续工作
非堆叠双ToR引入新问题:如何在没有直接连接的情况下同步两个不同ToR的状态
- 传统堆叠式双ToR:两个不同ToR直接连接,可以协商一个共享的sysID,主机可以通过链路聚合控制协议LACP与双ToR通信
- 非堆叠双ToR:消除ToR之间连接,使之相互独立。通过定制的LACP模块令双ToR交换机在LACP协商过程中,使用相同MAC地址和不同的端口号,使主机通过LACP与双ToR通信
3.2 HPN拓扑架构设计支持扩展
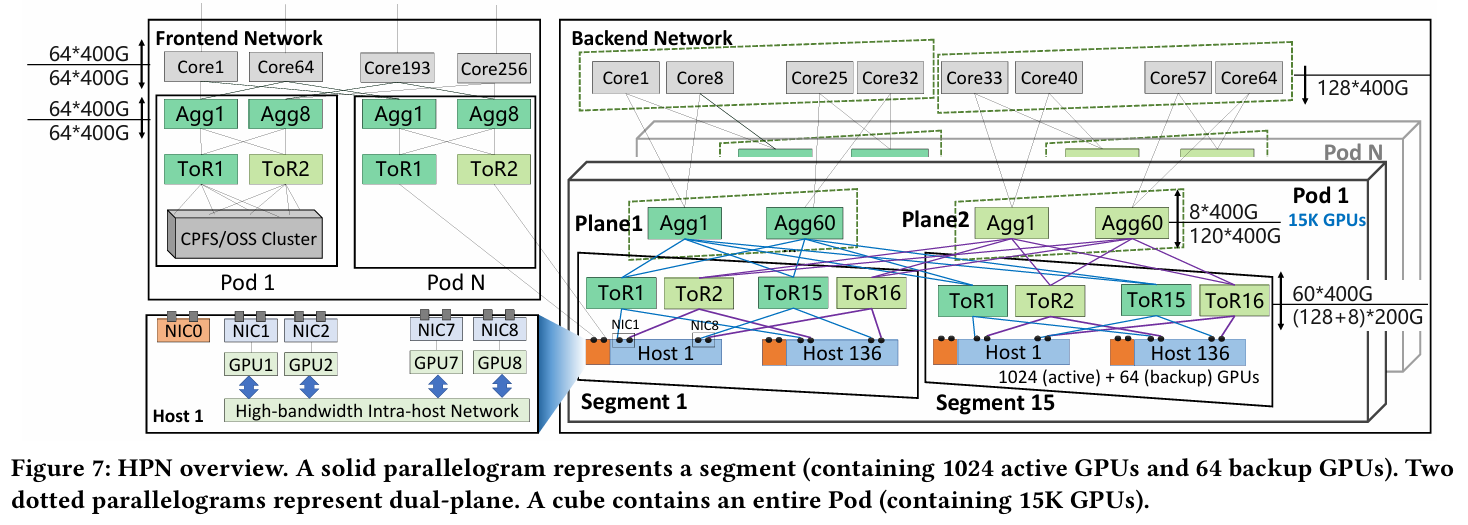
- Host:8张GPU使用NVLink链接,配8个网卡(除NIC0是备用网卡连接备用主机)
- Segment:每个网卡的两个端口连接到两个不同的ToR交换机,添加链路冗余(136台服务器,1088张GPU,千卡级别)
- Pod:通过平台层连接15个Segment(16,320张GPU,万卡级别,仅仅两层交换机)
- Core:通过连接个Pod,双平面设计,预先设置每个端口哈希来确保从物理端口流向
3.3 架构优势
segment层
- 容错,链路冗余:每个GPU对应的NIC两个端口分别连接到不同的ToR交换机
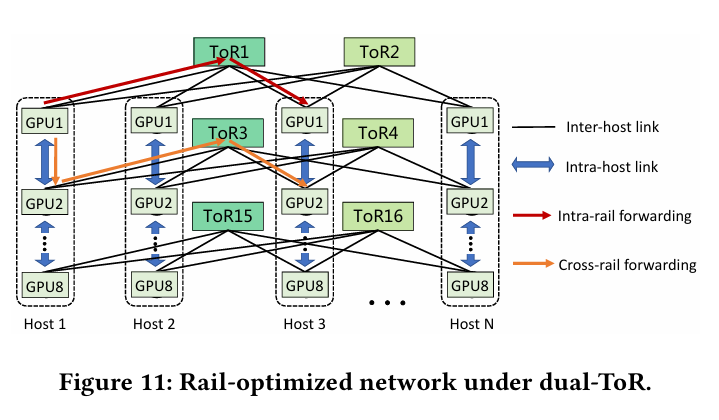
- 多轨通信:不同轨道的NIC可以通过主机内+主机间转发的组合进行通信(Figure 11)
- 通信优化:千卡通信只经过一个交换机,提高传输效率
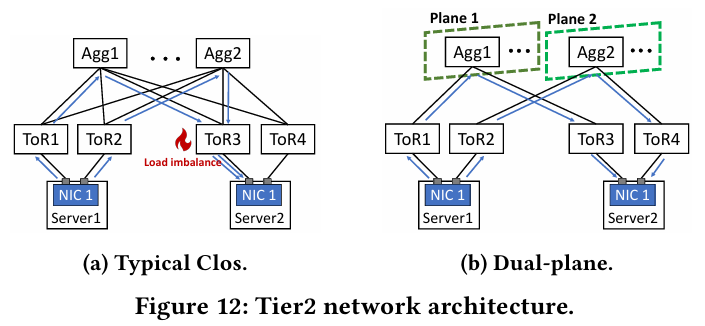
Pod层分组设计
双平面设计(Dual-plane):传统的spine-leaf结构(a)采用ECMP时会出现哈希碰撞问题,采用双平面设计(b),组与组的流量不会流到一起不会冲突
两层交换机实现万卡集群通信:万卡通信只需要通过两层的3个交换机
Core层
- 十万卡集群支持,5个交换机
- 并行策略,降低Core层流量
- 减少流量冲突和负载不均衡
4. 部署结果
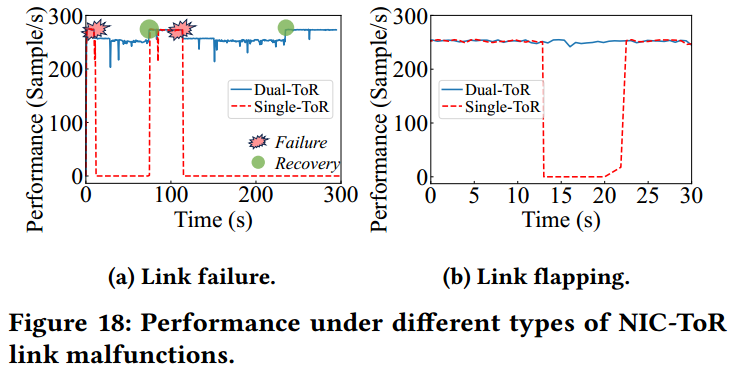
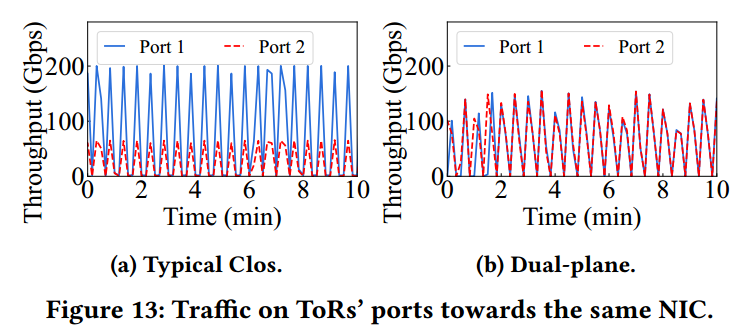
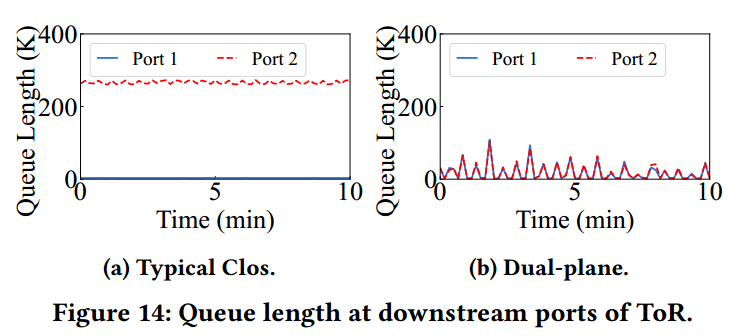
可靠性验证:该方案已部署使用超过8个月(2024.8.4前数据),未发生ToR导致的单点失效(Figure 18.a),在NIC-ToR链路故障时,双ToR涉及仅导致6.2%性能波动,而单ToR方案则会导致训练直接中断(Figure 18.b),同时非堆叠双ToR设计有效缓解了链路拥塞(Figure 13、14)
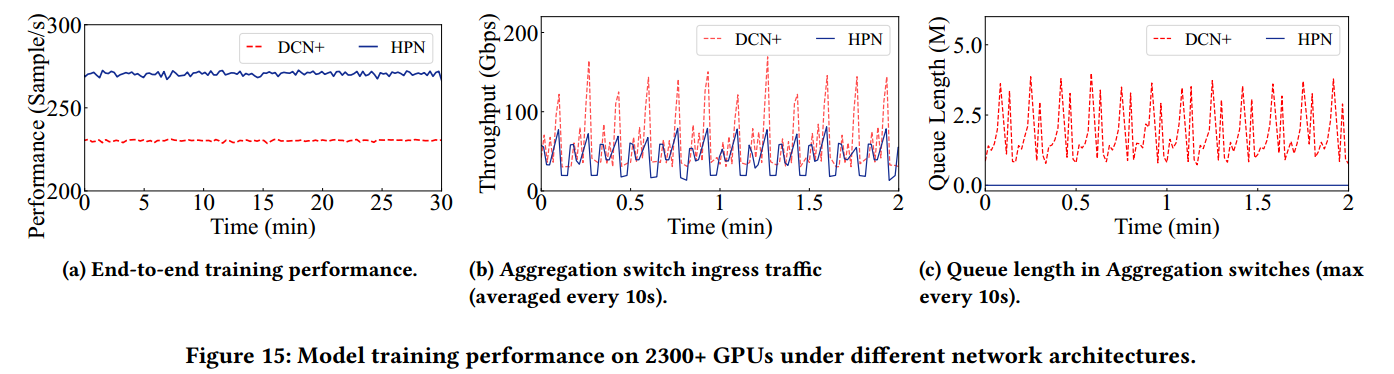
网络状况改善:在 2300+ GPU 规模的生产模型训练中,HPN 相比传统 DCN+ 架构,吞吐量提升了14.9% (Figure 15.a),跨 Segment 流量平均减少了37%(Figure 15.b),汇聚交换机的下行队列积压问题得到显著缓解 (Figure 15.c)
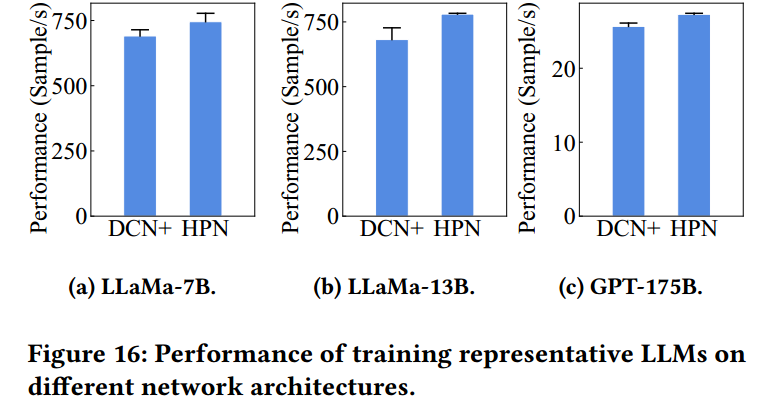
端到端性能提升: 大模型训练表现分别提升7.9%、14.4%和6.3%(Figure 16)
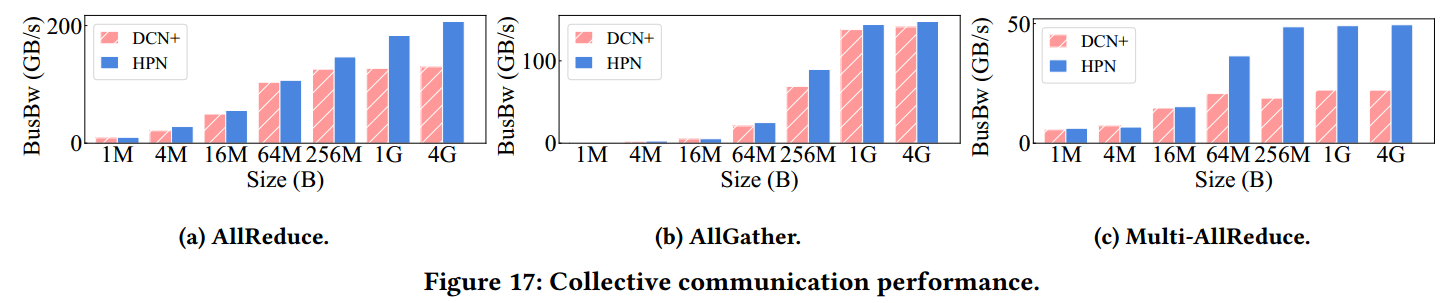
通信算子加速:AllReduce 性能提升高达59.3%(Figure 17.a),Multi-AllReduce 性能提升达158.2%(Figure 17.c),这主要归功于更好的负载均衡和跨段流量的减少
5. 阅读心得
阿里这篇文章将传统的三层架构设计简化为两层,并通过双平面设计将链路连接数量减半、多轨设计优化布线等技术,减少路径选择的搜索空间,降低哈希碰撞概率,让流量分布更可控,同时还减少了30%的成本,节省的成本可以连接更多的ToR交换机,容纳更多服务器与GPU
这种对架构直接的简化,反而让我思考,在面对复杂的性能瓶颈时,不应一味地陷入追求更复杂的路由算法这一思维定势,应该更加全面地审视问题,当前简化架构也并不意味着算法不再重要,可以考虑将简洁架构与自适应路由算法有机结合,在良好的架构的基础上用算法做更针对性的优化
6. 作者背景
第一作者:钱坤,阿里云网络研究科学家,负责设计和实施可预期网络(predictable network)的创新,目前组织开发用于AI训练/推理集群的网络监控与诊断系统,重点研究构建计算和存储系统的高性能网络解决方案
作者CV: https://qiankun11516.github.io/
7. 参考资料
- Kun Qian, Yongqing Xi, Jiamin Cao, Jiaqi Gao, Yichi Xu, Yu Guan, Binzhang Fu, Xuemei Shi, Fangbo Zhu, Rui Miao, Chao Wang, Peng Wang, Pengcheng Zhang, Xianlong Zeng, Eddie Ruan, Zhiping Yao, Ennan Zhai, and Dennis Cai, Alibaba HPN: A Data Center Network for Large Language Model Training. In Proceedings of the ACM SIGCOMM 2024 Conference (ACM SIGCOMM ‘24). Association for Computing Machinery, New York, NY, USA, 691–706. https://doi.org/10.1145/3651890.3672265,2024-8-4
- 阿里十万卡集群 网络拓扑架构和优势 Alibaba HPN: A Data Center Network for Large Language Model,https://www.bilibili.com/video/BV1xSvDeNEo6/?vd_source=dd2b7c41f54e83182372ee62c303b855,2024-8-3
- 国内大厂万卡AI集群网络洞察!看国内阿里、字节、腾讯是如何搭建万卡AI集群,https://www.bilibili.com/video/BV1FXnEzpEPZ/?spm_id_from=333.337.search-card.all.click&vd_source=dd2b7c41f54e83182372ee62c303b855,2025-9-27
- Remote direct memory access - Wikipedia,https://en.wikipedia.org/wiki/Remote_direct_memory_access,2025-12-8
- RDMA over Converged Ethernet - Wikipedia,https://en.wikipedia.org/wiki/RDMA_over_Converged_Ethernet,2025-12-13